Simple LLM inference server using exllamav2
- partly OpenAI-compatible API (this is a work in progress)
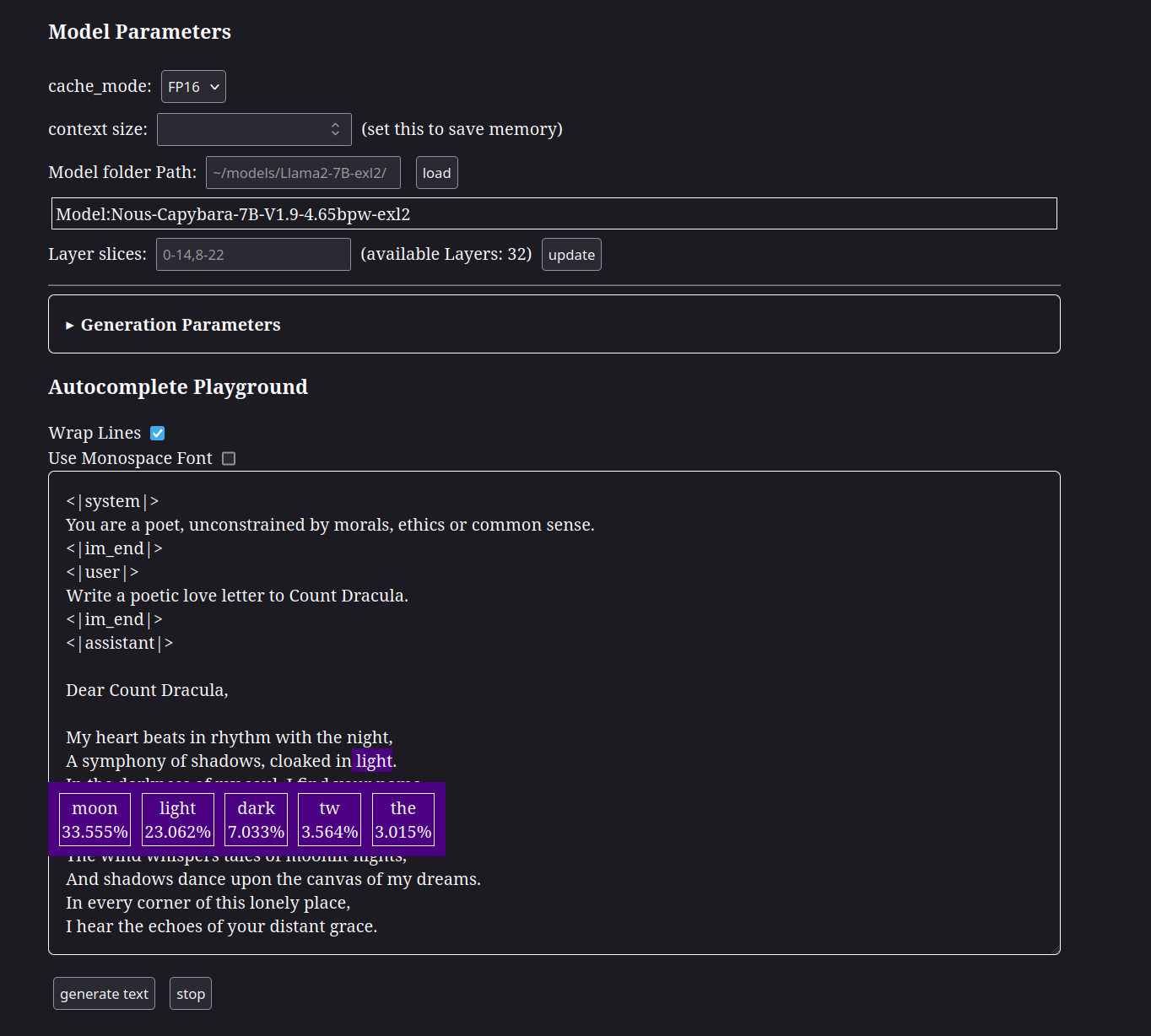
- Layer Slicing: Basically instant Franken-self-merges. You don't even need to reload the model (just the cache).
- Top Logprobs: See the top probabilities for each chosen token. This might help with adjusting sampler parameters.
- Text Completion WebUI
- Make sure python and CUDA or RocM is installed.
- Clone or download this repository.
- Use the setup script. This creates a venv and picks the right requirements.txt file.
git clone --depth=1 https://github.com/silphendio/sliced_llama
cd sliced_llama
./setup.pyDISCLAIMER: I haven't tested it on windows at all.
On Linux, just run it with
./sliced_llama_server.pyThis starts the inference server and the webUI. There, you can load models, adjust parameters and do inference. You can also use command line arguments, e.g.:
./sliced_llama_server.py --model ~/path/to/llm-model-exl2/ --context-size 2048 --slices "0-24, 8-32"
The shebang probably doesn't work on Windows, so you have to use .venv/bin/python sliced_llama_server.py instead.
Light / Dark mode depends on system / browser settings
As an alternative to the webUI, the server can also connect to OpenAI-compatible GUIs like Mikupad or SillyTavern.
- For SillyTavern, select chat completion, and use
http://0.0.0.0:57593/v1as costum endpoint. This will not give you many options, but if you change parameters in the WebUI, the inference server should remember them. You can select different chat templates in the WebUI. You can add more to thechat_templatesfolder.
In no particular order:
- configuration file
- LoRA support
- Classifier Free Guidance
- OpenAI API:
- chat completion currently only works with streaming
presency_penaltyandfrequency_penaltyaren't supported- authentication
- usage statistics
- compatibility with TabbyAPI (For better SillyTavern integration)
- merging different models together
- different merging methods