- Providing valuable insights into the latest models, including number of parameters, fine-tuning datasets and techniques, and hardware specifications.
- Practical guides for LLM alignment post-training, include dataset, benchmark datasets, efficient training libraries and techniques; also involves short insight of pre-trained LLMs.
- Explore from pre-training models to post-training models, interesting things you will get.
- Catalog
- Pre-trained Base Models
- Licences
- Open Source Aligned LLMs
- Instruction and Conversational Datasets
- Pre-training Datasets
- Efficient Training
- Evaluation Benchmark
- Multi-Modal LLMs
- Tool Learning
- Star History
Simple Version
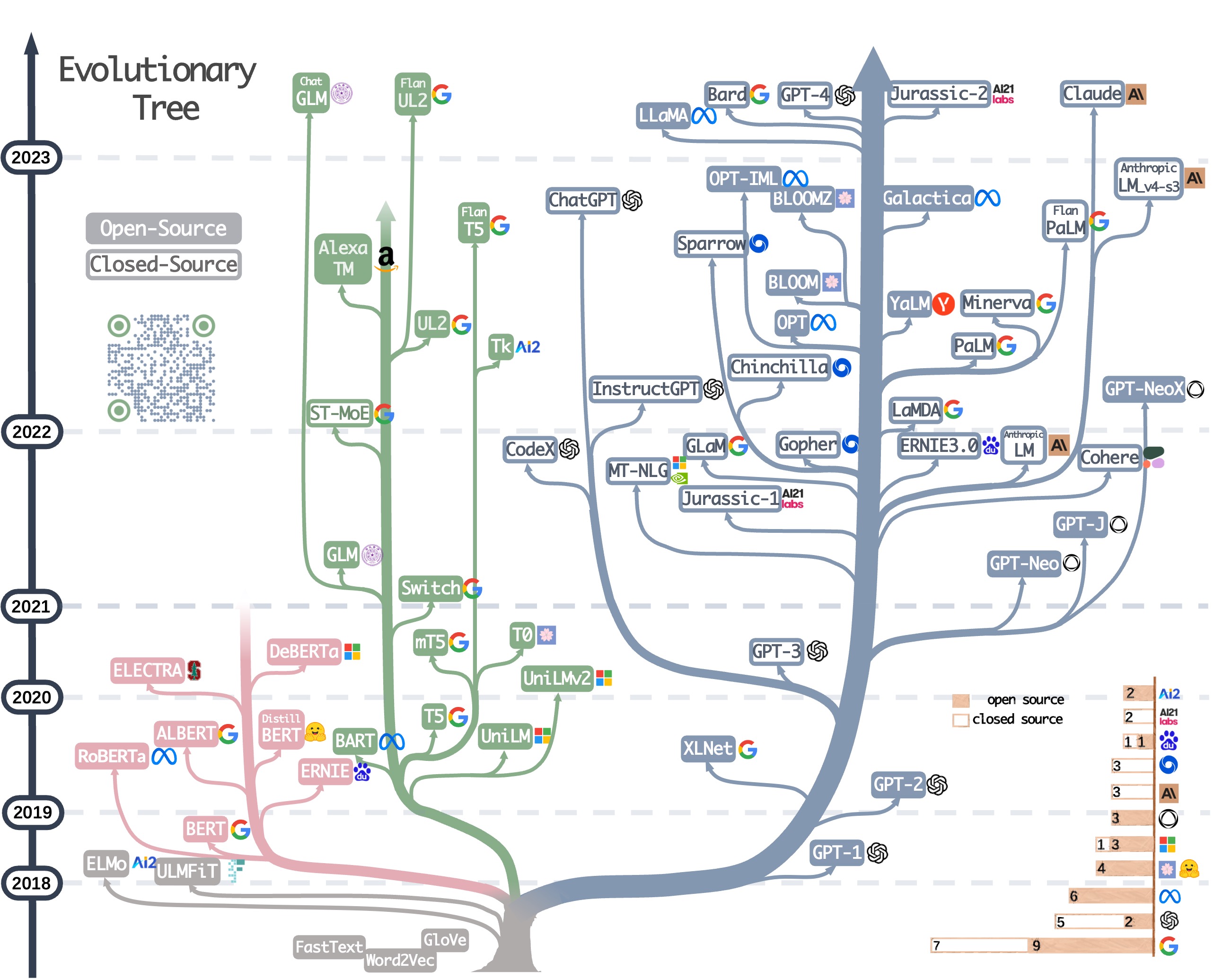
- OpenAI: GPT-1, GPT-2, GPT-3, InstructGPT, Code-davinci-002, GPT-3.5, GPT-4(-8k/32k)
- Anthropic: Claude-v1, Claude Instant
- Meta: OPT, Galactica, LLaMA
- huggingface BigScience: BLOOM (176B), BLOOMZ, mT0
- EleutherAI: GPT-Neo, GPT-J (6B), GPT-NeoX (20B), Pythia
- TogetherCompute: GPT-JT, RedPajama-7B, RedPajama-INCITE
- Berkeley: OpenLLaMA
- MosaicML: MPT-7B, MPT-7B-Instruct/Chat
- TII: Falcon-7/40B-(instruct)
- BlinkDL: RWKV-4-Pile, RWKV-4-PilePlus
- Tsinghua THUDM: GLM-130B, ChatGLM-6B
- Cerebras: Cerebras-GPT
- Google: T5, mT5, LaMDA, Pathways, PaLM, UL2, Flan-T5, Flan-UL2, Bard, PaLM-E, PaLM 2, MoE, Switch Transformer, GLaM, ST-MoE, MoE Routing
- DeepMind: Gopher, Chinchilla, Sparrow
- Nvidia: Megatron-Turing NLG (530B)
- AI21 Studio: Jurassic-1, Jurassic-2

- OpenAI
- 2018/06, GPT-1 (117m)
- 2019/02, GPT-2 (1.5B)
- 2020/06, GPT-3 (175B): ada(350M), babbage(1.3B), curie(6.7B), davinci(175B), detail here
- 2022/01, InstructGPT-3: text-ada(350M), text-babbage(1.3B), text-curie(6.7B), text-davinci-001(175B)
- 2022/02, Code-davinci-002
- GPT-3.5 (175B): text-davinci-002 (2022/03), text-davinci-003 (2022/11), ChatGPT (2022/11), gpt-3.5-turbo (2023/03)
- 2023/03, GPT-4(-8k/32k)
- Anthropic
- Claude-v1: 2023/03, state-of-the-art high-performance model, context window 9k/100k tokens
- Claude Instant: 2023/03, lighter, less expensive, and much faster option, context window 9k/100k tokens
- Meta
- OPT (125M/350M/1.3B/2.7B/6.7B/13B/30B/66B/175B): 2022/03, pre-trained on (datasets used in RoBERTa, the Pile,
PushShift.ioReddit) using metaseq, 1/7th the carbon footprint if GPT-3, combining Meta’s open source Fully Sharded Data Parallel (FSDP) API and NVIDIA’s tensor parallel abstraction within Megatron-LM, contain predominantly English text and a small amount of non-English data via CommonCrawl, released under a noncommercial license. - OPT-IML (30B/175B): 2022/12, create OPT-IML Bench, a large benchmark for Instruction MetaLearning (IML) of 2000 NLP tasks; train OPT-IML which are instruction-tuned versions of OPT
- Galactica (125M/1.3B/6.7B/30B/120B): 2022/11, facebook/galactica models are designed to perform scientific tasks, include prompts in pre-training alongside the general corpora, under a non-commercial CC BY-NC 4.0 license
- LLaMA (7B/13B/33B/65B): 2023/02, trained LLaMA 65B/33B on 1.4 trillion tokens, LLaMA 7B on one trillion tokens, chose text from the 20 languages with the most speakers, leaked, under a non-commercial GPL-3.0 license.
- OPT (125M/350M/1.3B/2.7B/6.7B/13B/30B/66B/175B): 2022/03, pre-trained on (datasets used in RoBERTa, the Pile,
- huggingface BigScience
- BLOOM (176B): 2022/07/11, a multilingual LLM trained on ROOTS corpus (a composite collection of 498 Hugging Face datasets), using 250k vocabulary sizes, seq-len 2048, smaller size model search here, release under commercial friendly BigScience Responsible AI License.
- BLOOMZ & mT0: 2022/11, finetune BLOOM & mT5 on our crosslingual task instruction following mixture (xP3), released under commercial friendly bigscience-bloom-rail-1.0 License.
- EleutherAI
- The Pile: 2020/12/31, a 300B (deduplicated 207B) token open source English-only language modelling dataset, download here.
- GPT-Neo (125M/1.3B/2.7B)(Deprecated): 2021/03/21, A set of decoder-only LLMs trained on the Pile, MIT license.
- GPT-J (6B): 2021/06/04, EleutherAI/gpt-j-6b, English language model trained on the Pile using mesh-transformer-jax library, seq-len 2048, Apache-2.0 license.
- GPT-NeoX (20B): 2022/02/10, EleutherAI/gpt-neox-20b, English language model trained on the Pile using GPT-NeoX library, seq-len 2048, Apache-2.0 license.
- Pythia (70M/160M/410M/1B/1.4B/2.8B/6.9B/12B): 2023/02/13, a suite of 8 model sizes on 2 different datasets: the Pile, the Pile deduplication, using gpt-neox library, seq-len 2048, Apache-2.0 license.
- TogetherCompute
- GPT-JT (6B): 2022/11/29, A fork of GPT-J-6B, fine-tuned on 3.53 billion tokens with open-source dataset and techniques, outperforms most 100B+ parameter models at classification.
- RedPajama-Pythia-7B: 2023/04/17, release RedPajama-Data-1T for reproducing "LLaMA" foundation models in a fully open-source way; 40% RedPajama-Data-1T trained RedPajama-Pythia-7B beat Pythia-7B trained on the Pile and StableLM-7B with higher HELM score, still weaker than LLaMA-7B for now; detail see blog1, blog2 and Card.
- OpenChatKit: 2023/03/10, fine-tuned for chat from EleutherAI’s GPT-NeoX-20B with over OIG-43M instructions dataset; contributing to a growing corpus of open instruction following dataset.
- RedPajama-INCITE (3B/7B): 2023/05/05, open-source 3B model (base/chat/instruct) trained on 800B tokens and finetuned, the strongest model in it’s class and brings LLM to a wide variety of hardware; 80% (800B) trained 7B model beat same class GPT-J/Pythia/LLaMA on HELM and lm-evaluation-harness; releasing RedPajama v2 with 2T Tokens (mix the Pile dataset into RedPajama, more code like the Stack); Apache 2.0 license.
- Berkeley/OpenLLaMA: open source reproduction of Meta AI’s LLaMA 7B/3B trained on the RedPajama dataset, provide PyTorch and JAX weights, Apache-2.0 license.
- MosaicML
- MPT (MosaicML Pretrained Transformer, 7B(6.7B)): 2023/05/05, a GPT-style decoder-only transformers trained from scratch on 1T tokens of text and code (RedPajama, mC4, C4, the Stack Dedup, Semantic Scholar ORC) in 9.5 days at a cost of ~$200k, ALiBi (handle 65k long input) and other optimized techniques, matches the quality of LLaMA-7B; open source for commercial use, Apache-2.0 License.
- MPT-7B-Instruct/Chat: finetuning MPT-7B on instruction following dataset and dialogue generation dataset; release mosaicml/dolly_hhrlhf dataset derived from Databricks Dolly-15k and Anthropic’s Helpful and Harmless datasets; CC-By-SA-3.0 (commercially-usable) / CC-By-NC-SA-4.0 (non-commercial use only).
- TII (Technology Innovation Institute)
- Falcon-7/40B-(instruct): 2023/05/26, pretrained on 1500/1000B tokens of RefinedWeb (apache-2.0) enhanced with curated corpora, finetuned on a mixture of chat/instruct datasets like Baize, No. 1 at huggingface Open LLM Leaderboard at the end of May 2023; change license to Apache 2.0 on June 01.
- BlinkDL
- RWKV-4-Pile (169M/430M/1.5B/3B/7B/14B): 2023/04, RWKV: Reinventing RNNs for the Transformer Era, leverages RNN with a linear attention mechanism, trained on the Pile, infinite seq-len, Weights.
- RWKV-4-PilePlus (7B/14B): 2023/04, finetuning on [RedPajama + some of Pile v2 = 1.7T tokens].
- Tsinghua THUDM
- GLM-130B: 2022/10, An Open Bilingual Pre-Trained Model, support english and chinese, trained on 400B text tokens using GLM library, Apache-2.0 license.
- ChatGLM-6B: 2023/03, trained with 1T chinese and english tokens, finetuned with instruction following QA and dialogue dataset in chinese language, released under Apache-2.0 license, authorization needed.
- Cerebras
- Cerebras-GPT: 2023/03, a family of seven GPT models ranging from 111M to 13B, trained Eleuther Pile dataset using the Chinchilla formula, release under the Apache 2.0 license
- Google
- 2019/10/23, T5, Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- 2020/01/28, LaMDA: blog-2021/03/18, blog-2020/01/28, blog-2022/01/21
- 2021/10/28, Introducing Pathways: A next-generation AI architecture
- 2022/04/04, Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance
- 2022/05/11, Language Models Perform Reasoning via Chain of Thought
- 2022/10/14, UL2 20B: An Open Source Unified Language Learner
- 2023/02/01, FLAN: Introducing at 2021/10/06; Flan 2022 Collection for instruction tuning release here; first used in Flan-T5 and Flan-PaLM at 2022/10/20, achieved significant improvements over PaLM; Flan-UL2
- 2023/02/06, Introducing Bard
- 2023/03/10, PaLM-E: An embodied multimodal language model.
- 2023/05/10, Introducing PaLM 2, review the technical report
- MoE: Sparsely-Gated Mixture-of-Experts layer (MoE) 2017/01, Switch Transformer 2021/01, GLaM 2021/12, ST-MoE 2022/02, MoE Routing 2022/11
- DeepMind
- 2021/12, Gopher (280B), SOTA LLM could do instruction-following and dialogue interaction
- 2022/04, Chinchilla (70B), a 4x smaller model trained on 4x more data (1.3T) outperform Gopher
- 2022/09, Sparrow, Building safer dialogue agents; designed to talk, answer, and search using Google, supports it with evidence
- Nvidia
- 2019/09, Megatron-Turing NLG (530B), largest model trained with novel parallelism techniques of Nvidia
- AI21 Studio
- Jurassic-1 (J1, 2021/08): J1-Jumbo 178B, J1-Grande 17B, J1-Large 7.5B; 250k token vocab;
- Jurassic-2 (J2, 2023/03): Announcing Blog
- Apache 2.0: Allows users to use the software for any purpose, to distribute it, to modify it, and to distribute modified versions of the software under the terms of the license, without concern for royalties.
- MIT: Similar to Apache 2.0 but shorter and simpler. Also, in contrast to Apache 2.0, does not require stating any significant changes to the original code.
- CC-BY-SA-4.0: Allows (i) copying and redistributing the material and (ii) remixing, transforming, and building upon the material for any purpose, even commercially. But if you do the latter, you must distribute your contributions under the same license as the original. (Thus, may not be viable for internal teams.)
- CC-By-NC-SA-4.0: NC for non-commercial.
- BSD-3-Clause: This version allows unlimited redistribution for any purpose as long as its copyright notices and the license's disclaimers of warranty are maintained.
- OpenRAIL-M v1: Allows royalty-free access and flexible downstream use and sharing of the model and modifications of it, and comes with a set of use restrictions (see Attachment A)
- 05/26: Falcon-40B, foundational LLM with 40 billion parameters trained on one trillion tokens, first place at huggingface Open LLM Leaderboard for now, 7B also released (blog, model, Leaderboard)
- 05/25: BLIP-Diffusion, a BLIP multi-modal LLM pre-trained subject representation enables zero-shot subject-driven image generation, easily extended for novel applications (tweet, blog)
- 05/24: C-Eval, is a comprehensive Chinese evaluation suite for foundation models. It consists of 13948 multi-choice questions spanning 52 diverse disciplines and four difficulty levels (tweet, repo)
- 05/24: Guanaco-QLoRA, 33B/65B model finetuned on a single 24/48GB GPU in only 12/24h with new QLoRA 4-bit quantization, using small but with quality dataset OASST1 (tweet, repo, demo)
- 05/23: MMS (Massively Multilingual Speech), release by Meta AI, Can do speech2text and text speech in 1100 languages, half the word error rate of OpenAI Whisper, covers 11 times more languages. (tweet, blog, repo)
- 05/22: Stanford AlpacaFarm, AlpacaFarm replicates the RLHF process at a fraction of the time (<24h) and cost ($<200), enabling the research community to advance instruction following research (blog, repo)
- 05/22: LIMA, Less is More for Alignment (Meta AI), LLaMA 65B + 1000 standard supervised samples = {GPT4, Bard} level performance, without RLHF. (tweet, paper)
- 05/21: 4-bit QLoRA via bitsandbytes (4-bit base model + LoRA) (tweet)
- 05/20: InstructBLIP Vicuna-13B, generates text based on text and image inputs, and follows human instructions. (tweet, demo, repo)
- 05/18: CodeT5+, LLM for code understanding and generation (tweet, blog)
- 05/18: PKU-Beaver, the first chinese open-source RLHF framework developed by PKU-Alignment team at Peking University. Provide a large human-labeled dataset (up to 1M pairs) including both helpful and harmless preferences to support reproducible RLHF research. (blog, repo, data)
- 05/17: Tree of Thoughts(TOT), GPT-4 Reasoning is Improved 900% with this new prompting (video, paper, repo)
- 05/13: LaWGPT, a chinese Law LLM, extend chinese law vocab, pretrained on large corpus of law specialty (repo)
- 05/10: Multimodal-GPT, a multi-modal LLM Based on the open-source multi-modal model OpenFlamingo support tuning vision and language at same time, using parameter efficient tuning with LoRA (tweet, repo)
- 05/10: DetGPT, a multi-modal LLM addressing reasoning-based object detection problem, could interpret user instruction and automatically locate the object of interest, with only little part of whole model fine-tuned. (blog, repo)
- 05/10: SoftVC VITS Singing Voice Conversion, A open-source project developed to allow the developers' favorite anime characters to sing. Popular for it's been used in song generation with perticular singer's voice. (repo)
- 05/10: ImageBind, One Embedding Space To Bind Them All (FAIR, Meta AI), learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. It enables novel emergent applications ‘out-of-the-box’ with small fine-tune dataset. (tweet, blog, repo)
- 05/04: TIP(Dual Text-Image Prompting), a DALLE2/StableDiffusion-2 enhanced LLM that can generate coherent and authentic multimodal procedural plans toward a high-level goal (tweet)
- 05/04: GPTutor, a ChatGPT-powered tool for code explanation (tweet)
- 05/04: Chatbot Arena: Benchmarking LLMs in the Wild with Elo Ratings (blog, tweet)
- 05/03: Modular/Mojo, a new Python-compatible language with a parallelizing compiler that can import Python libraries, combines the usability of Python with the performance of C, unlocking unparalleled programmability of AI hardware and extensibility of AI models. Only Limited notebook released for now. (tweet, blog, doc)
- 05/01: VPGTrans: Transfer Visual Prompt Generator across LLMs, a multi-modal LLM release by NUS for its 10 times training cose reduced. (blog, repo)
- 05/01: "Are Emergent Abilities of Large Language Models a Mirage?" alternative explanation for emergent abilities, strong supporting evidence that emergent abilities may not be a fundamental property of scaling AI models. (paper)
- 05/01: A brief history of LLaMA models (tweet, blog)
- 05/01: Geoffrey Hinton left Google. IBM say it can replace over 7500 current employees with AI. Chegg stock price drop 40%.
- 04/30: PandaLM, provide reproducible and automated comparisons between different large language models (LLMs). (tweet, repo)
- 04/30: Otter, a Multi-modal chatbots learn to perform tasks through rich instructions on media content (tweet, repo)
- 04/30: Linly-ChatFlow, Shenzhen University release Linly-ChatFlow-7B/13B/33B/65B fintune on pre-trained Chinese-LLaMA with english and chinese intruction dataset (repo)
- 04/29: MLC-LLM, an open framework that brings LLMs directly into a broad class of platforms (iPhone, CUDA, Vulkan, Metal) with GPU acceleration! (tweet, blog repo)
- 04/29: Lamini: The LLM engine for rapidly customizing models without spinning up any GPUs (tweet, blog, repo, doc)
- 04/29: FastChat-T5, a compact and commercial-friendly chatbot, Fine-tuned from Flan-T5, Outperforms Dolly-V2 with 4x fewer parameters (tweet, repo)
- 04/29: StabilityAI/StableVicuna, Carper AI from StabilityAI family release RLHF-trained version of Vicuna-13B! (tweet, blog, model)
- 04/29: StabilityAI/DeepFloyd IF, a powerful text-to-image model that can smartly integrate text into images, utilizes T5-XXL-1.1 as text encoder (tweet, blog)
- 04/29: MosaicML/SD2, Training Stable Diffusion from Scratch for <$50k with MosaicML (tweet, blog)
- 04/29: gpt4free, use gpt-4/3.5 free from sites (repo)
- 04/29: OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks such as single-agent, multi-agent, and natural language. Developed based on PyTorch by chinese company 4paradigm (repo)
- 04/28: Chinese-LLaMA-Plus-7B, re-pretrain LLaMA on larger(120G) general corpus, fine-tune with 4M instruction dataset, bigger LoRA rank for less precision loss, beat former 13B mdoel on benchmark (repo)
- 04/28: AudioGPT, a multi-modal GPT model can understand audio/text/image instruction inputs and generate audio, song, style transfer speech, talking head synthesis video (blog, repo, demo)
- 04/28: Multimodal-GPT, released by the famous MMLab, build base on open-source multi-modal model OpenFlamingo with visual and language instructions (repo)
- 04/27: "Speed is all you need", generate a 512 × 512 image with 20 iterations on GPU equipped mobile devices in 12- seconds for Stable Diffusion 1.4 without INT8 quantization, 50+% latency reduced on Samsung S23 Ultra. (paper)
- 04/27: replit-code-v1-3b, it's a 2.7B parameters LLM trained entirely on code in 10 days, performs 40% better than comparable models on benchmark (tweet, model)
- 04/26: LaMini-LM, a diverse set of 15 (more coming) mini-sized models (up to 1.5B) distilled from 2.6M instructions, comparable in performance to Alpaca-7B in downstream NLP + human eval (tweet, repo, data)
- 04/26: huggingChat, a 30B OpenAssistant/oasst-sft-6-llama-30b-xor LLM deployed by huggingface (tweet, site, model)
- 04/26: LLM+P, takes in a planning problem decription, turn it into PDDL, leveraging classical planners to find a solution (tweet, paper, repo)
- 04/25: NeMo Guardrails, the new toolkit for easily developing trustworthy LLM-based conversational applications (tweet)
- 04/21: China Fudan University release its 16B LLM named MOSS-003; Moss dataset contains ~1.1M text-davinci-003 generated self-instruct dataset, include ~300k plugins dataset as text-to-image/equations/.etc, fp16 finetune on 2 A100s or 4/8-bit finetune on single 3090. (repo)
- 04/21: Phoenix, a new multilingual LLM that achieves competitive performance, vast collection of popular open source dataset (repo)
- 04/20: UltraChat, a Informative and Diverse Multi-round Chat Data gather by THUNLP lab (repo, data)
- 04/20: replicate ChatGLM with efficient fine-tuning (ptunig, lora, freeze) (repo); support langchain in langchain-ChatGLM project
- 04/19: StableLM, 3B/7B LLM from StabilityAI (tweet, blog)
- 04/18: Semantic Kernel, MSFT release its contextual memory tool like langchain/gptindex (repo)
- 04/17: LLaVA: Large Language and Vision Assistant, Visual Instruction Tuning (blog, repo, demo)
- 04/17: MiniGPT-4, multi-modal LLM like GPT4, consists of a vision encoder with a pretrained ViT and Q-Former, a single linear projection layer, and an advanced Vicuna large language model (blog, repo)
- 04/17: TogetherCompute/RedPajama, reproduce LLaMA with 1.2 trillion tokens (blog, tweet)
- 04/16: LAION-AI/Open-Assistant, is an open-source chat model(includes datasets: consists of a ~161K human-annotated assistant-style conversation corpus, including 35 different languages and annotated with ~461K quality ratings) (tweet, repo, mdoels)
- 04/15: WebLLM, an open-source chatbot that brings LLMs like Vicuna directly onto web browsers (tweet, blog, repo)
- 04/12: Dolly-v2-12b, Databricks release its open source Dolly-v2-12b model, derived from EleutherAI’s Pythia-12b and fine-tuned on a ~15K record instruction corpus generated by Databricks employees, which is open source as well (blog, repo, model)
- 04/12: DeepSpeed Chat, DeepSpeed from MSFT support RLHF fine-tune with affordable haraware (blog)
- 04/12: Text-to-SQL from self-debugging explanation component (tweet)
- 04/11: AgentGPT, generative agents were able to simulate human-like behavior in an interactive sandbox (tweet)
- 04/11: AutoGPT, autonomously achieve whatever goal you set (repo)
- 04/11: Raven v8 14B released (tweet, model, repo)
- 04/09: SVDiff, diffusion fine-tune method smaller than LoRA (tweet, repo)
- 04/09: RPTQ, new 3 bit quantization (repo, paper)
- 04/08: Wonder Studio, robot beat human with kongfu (tweet)
- 04/08: chatGDB, chatgpt for GDB (tweet, repo)
- 04/08: Vicuna-7B, small yet capable (repo), Vicuna shows impressive performance against GPT4 by lastest paper of MSFTResearch (tweet)
- 04/07: Instruction tuning with GPT4, academic self-instruct guide from microsoft research (tweet, blog, repo, paper)
- 04/07: ChatPipe, Orchestrating Data Preparation Program by Optimizing Human-ChatGPT Interactions (blog)
- 04/07: Chinese-LLaMA-Alpaca release its 13B model (tweet)
- 04/07: MathPrompter, How to chatwith GPT3 Davinci API and archive better on math benmark (paper)
- 04/07: engshell, interact with your shell using english language (tweet)
- 04/07: a chinese geek fine-tune a chatglm-6b model on his wechat dialogue and blog to produce a digital version of him self (tweet)
- 04/06: StackLLaMA, A hands-on guide to train LLaMA with RLHF, fine-tuned on stack exchange QA data (tweet, blog, demo)
- 04/06: Arxiv Chat, chat with the lastest papers (tweet)
- 04/06: Firefly, a 1.4B/2.6B chinese chat LLM, finetune on 1.1M multi-task dataset (repo)
- 04/06: a chinese guide of chatgpt repo
- 04/06: LamaCleaner, segment anything and inpaint anything (tweet)
- 04/05: SAM, Meta AI release Segment Anything Model as foundation model for image segmentation, and SA-1B dataset, which is 400x larger than any existing segmentation dataset (tweet)
- 04/04: a beautiful cli for chatgpt (tweet)
- 04/04: Baize, fine-tune with LoRA using 100K dialogs ChatGPT self-chat and other opensource dataset, released 7B, 13B and 30B models (repo, tweet, demo, model)
- 04/03: Koala-13B, fine-tuned from LLaMA on user-shared conversations and open-source datasets, performs similarly to Vicuna (blog, demo, repo)
- 04/02: LMFlow, train on single 3090 for 5 hours and get your own chatgpt (blog, repo)
- 04/01: Alpaca-CoT, extend CoT data to Alpaca to boost its reasoning ability, provide gathered datasets (repo)
- 04/01: Vicuna-13B, An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality, fine-tune LLaMA on ~70K conversations from ShareGPT (blog, repo, demo, data, gptq-4-bit)
- 04/01: Twitter's Recommendation Algorithm (repo)
- 04/01: PolyglotSiri Apple Shortcut, (tweet, repo)
- 04/01: Official Apple Core ML Stable Diffusion Library, M-series chips beat 4090, (repo, MochiDiffusion, swift-coreml-diffusers)
- 03/31: BloombergGPT, 50B LLM outperform existing models on financial tasks (tweet)
- 03/31: HuggingGPT, as an interface for LLMs to connect AI Models for solving comlicated AI tasks (tweet, demo)
- 03/31: Llama-X (repo)
- 03/31: GPT4 UI generation (tweet)
- 03/30: ChatExplore (tweet)
- 03/30: ColossalChat, from ColossalAI (demo, tweet, medium, repo, serve)
- 03/30: ChatGLM-6B, from THUDM(Tsinghua University), code and data not release (repo, model)
- 03/29: Uncle Rabbit, the first conversational holographic AI (tweet, blog)
- 03/29: chatgpt instead of siri (tweet)
- 03/29: LLaMA-Adapter, fine-tuning LLaMA with 1.2M learnable parameters in 1 hour on 8 A100 (tweet, repo, demo)
- 03/28: Chinese-LLaMA-Alpaca, add 20K chinese sentencepiece tokens to vocab and pre-trained LLaMA in 2 steps, fine-tuned LLaMA on a 2M chinese corpus using Alpaca-LoRA, 7B model released, dataset not (repo, tweet, blog, model)
- 03/28: gpt4all, fine-tune LLaMa using LoRA with ~800k gpt3.5-turbo generations, include clean assistant data including code, stories and dialogue (repo, model, data)
- 03/24: Dolly, Databricks fine-tune alpaca dataset on gpt-j-6b (repo)
- 03/22: Alpaca-LoRA-Serve, gradio based chatbot service (tweet, repo)
- 03/22: Alpaca-LoRA, reproducing the Stanford Alpaca results using low-rank adaptation(LoRA) on RTX4090 and run on a Raspberry Pi 4 (tweet, repo, demo, model, blog, reproduce tweet, zhihu, sina, explain)
- 03/22: BELLE, fine-tune BLOOMZ-7B1-mt and LLaMA(7B/13B) on a 1.5M chinese dataset generate in a alpaca way, (repo, model)
- 03/17: instruct-gpt-j, NLPCloud team fine-tune GPT-J using Alpaca's dataset (blog, model)
- 03/13: Stanford Alpaca, fine-tune LLaMA 7B with a 52K single-turn instruction-followling dataset generate from OpenAI’s text-davinci-003 (blog, repo)
- 03/11: ChatIE, solving Zero-Shot Information Extraction problem by enhancing ChatGPT with CoT prompting, achieve good performance on primary IE benchmarks (repo)
- prompt engineering guide (blog), openai best practices (blog), prompt prefect (blog), prompt searching (repo), PromptInject (repo), auto prompt engineering (blog)
- peft: State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods (repo)
- GPTQ-for-LLaMa: 4 bits quantization of LLaMA using GPTQ (repo)
- llama.cpp: Inference of LLaMA model in pure C/C++, support different hardware platform & models, support 4-bit quantization using ggml format (repo, alpaca.cpp); support python bindings (llama-cpp-python, pyllamacpp, llamacpp-python )
- llama_index: connect LLM with external data (repo), like langchain (repo)
- llama-dl: high speed download of LLaMA model (repo(deprecated), model)
- text-generation-webui: A gradio web UI for deploy LLMs like GPT-J, LLaMA (repo)
- tldream/lama-cleaner: tiny little diffusion drawing app (repo1, repo2)
- A1111-Web-UI-Installer: A gradio web UI for deploy stable diffusion models (repo)
- https://github.com/allenai/natural-instructions AllenAI NI dataset, a collection of over 1.6K tasks and their natural language definitions/instructions, more
- https://huggingface.co/datasets/bigscience/P3 BigScience P3 (Public Pool of Prompts), a collection of prompted English datasets covering 55 tasks.
- https://laion.ai/blog/oig-dataset/ The Open Instruction Generalist (OIG-43M) dataset is a large open source instruction dataset that currently contains ~43M instructions.
- https://huggingface.co/datasets/databricks/databricks-dolly-15k Dolly v2.0 dataset by DataBricks.
- https://huggingface.co/datasets/OpenAssistant/oasst1 OpenAssistant Conversations (OASST1), a human-generated, human-annotated assistant-style conversation corpus consisting of 161k messages in 35 different languages, annotated with 461k quality ratings, resulting in over 10,000 fully annotated conversation trees.
- https://huggingface.co/datasets/Anthropic/hh-rlhf Anthropic Helpful and Harmless (HH-RLHF) datasets, include (1) Human preference data about helpfulness and harmlessness, (2) Human-generated and annotated red teaming dialogues
- https://huggingface.co/datasets/mosaicml/dolly_hhrlhf MosaicMl's mix of Dolly-15K and Anthropic's HH-RLHF dataset
- https://huggingface.co/datasets/jeffwan/sharegpt_vicuna Vicuna's ShareGPT dialogue dataset
- https://huggingface.co/datasets/tatsu-lab/alpaca Alpaca's 50k instruction following dataset from ChatGPT
- https://huggingface.co/datasets/WizardLM/evol_instruct_70k WizardLM's dataset
- https://github.com/google-research/FLAN/tree/main/flan/v2 Google Flan Collection dataset
- OPT-IML Bench use in OPT-IML training
- https://huggingface.co/datasets/Hello-SimpleAI/HC3 Human ChatGPT Comparison Corpus (HC3)
- the Pile
- RedPajama-Data-1T
- C4
- mC4
- the Stack
- https://github.com/CarperAI/trlx CarperAI/trlx, a distributed training framework language models with RLHF; CarperAI, StabilityAI's FOSS RLHF lab, Spun out of EleutherAI
- https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-chat Microsoft DeepSpeed example
- https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat ColossalChat
- https://pytorch.org/docs/stable/fsdp.html PyTorch FSDP
- https://github.com/tloen/alpaca-lora Alpaca-LoRA
- https://github.com/ofirpress/attention_with_linear_biases ALiBi, [Train Short, Test Long: Attention with Linear Biases (ALiBi) Enables Input Length Extrapolation], handle extremely long inputs
- https://github.com/NVIDIA/FasterTransformer FasterTransformer, highly optimized transformer-based encoder and decoder component
- MosaicML: Composer, llm-foundry
-
Data & Model Parallel
- Data Parallel
- Tensor Parallel
- Pipeline Paralle
- Zero Redundancy Optimizer(ZeRO) (DeepSpeed, often work with CPU offloading)
- Sharded DDP(FSDP)
- Mixture-of-Experts (MoE)
-
Param Efficient
- PEFT
- LoRA [2021/10, Microsoft]
- Prompt Tuning [2021/09, Google]
- Prefix-Tuning [2021/01, Stanford]
- P-tuning [2021/03, Tsinghua, Peking, BAAI]
- P-tuning v2 [2022/03, Tsinghua, BAAI]
- PEFT
-
Other
- Checkpointing
- Offloading(ZeRO)
- Memory Efficient Optimizers
- 16-bit mix precision
- 8-bit: bitsandbytes / triton
- 4-bit: gptq / ggml
- https://github.com/hendrycks/test MMLU, 2020/09, covers 57 tasks including elementary mathematics, US history, computer science, law, and more; regularly groups with science/social science/math/med/humanities.
- https://github.com/EleutherAI/lm-evaluation-harness 2021/09, 200+ task implemented(hundreds/thousands/ten-thousands for each), industry-standard ICL evaluation codebase, mpt example, more see report
- https://crfm.stanford.edu/helm/latest/ 2022/11, Stanford Holistic Evaluation of Language Models (HELM), covers 42 scenarios and 57 metrics
- https://github.com/google/BIG-bench 2022/06, collaborative benchmark covers more than 200 tasks
- https://github.com/suzgunmirac/BIG-Bench-Hard 2022/10, Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
- https://github.com/microsoft/AGIEval AGIEval, 2023/04, A Human-Centric Benchmark for Evaluating Foundation Models; AGIEval v1.0 contains 20 tasks, including two cloze tasks (Gaokao-Math-Cloze and MATH) and 18 multi-choice question answering tasks, derived from 20 official, public, hign-standard qualification human exams, like gaokao, SAT
- https://openai.com/research/truthfulqa TruthfulQA, 2021/09, a OpenAI benchmark for Measuring how models mimic human falsehoods, which comprises 817 questions that span 38 categories, including health, law, finance and politics
- https://github.com/google-research-datasets/seahorse Seahorse, 2023/05, is a compound dataset for summarization evaluation, it consists of 96K summaries with human ratings along 6 quality dimensions
- https://github.com/bigcode-project/bigcode-evaluation-harness 2022/11, evaluation of code generation models
- https://openai.com/research/evaluating-large-language-models-trained-on-code 2021/07, OpenAI Codex performance on HumanEval
- https://github.com/Felixgithub2017/MMCU Multi-task Chinese Understanding (MMCU, 2023/04), chinese version MMLU, four major domains including medicine, law, psychology, and education; apply free dataset download on email response
- https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/pro/examples/README.md 2023/04, Chinese-LLaMA project use this small chinese dataset (which contains 10 tasks, 20 samples for each) to test its own performace upgrade with OpenAI GPT API
- https://github.com/Hello-SimpleAI/chatgpt-comparison-detection Human ChatGPT Comparison Corpus (HC3, 2023/01), tens of thousands of comparison responses from both human experts and ChatGPT, with questions ranging from open-domain, financial, medical, legal, and psychological areas
- https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard 2023/05, 4 key benchmarks from the Eleuther AI Language Model Evaluation Harness
- https://lmsys.org/blog/2023-05-25-leaderboard/ Chatbot Arena leaderboard, Elo rating leaderboard based on the 27K anonymous voting
- https://github.com/deep-diver/LLM-As-Chatbot/tree/main/models deploy models as a chatbot service as example
- [GPT-4 Technical Report, OpenAI, 2023.03]
- [Sparks of Artificial General Intelligence: Early experiments with GPT-4, MSFT, 2023.04]
- [PaLM 2 Technical Report, Google, 2023.05]
- Plugins
- Web Browsing
- Planning
- Embodied AI