This project implements a web-based chatbot using the LangChain framework, phi-3 model as llm with ollama, chromadb as vectorDB and streamlit as frontend. The chatbot is designed to interact with users based on the content of a specified website.
- Web-based Interface: Users can interact with the chatbot through a web interface.
- Document Loading: The chatbot loads content from a specified website to understand the context of the conversation.
- Text Splitting: The content from the website is split into chunks for processing.
- Vector Store Creation: Chunks of text are converted into vectors and stored in a vector store for efficient retrieval.
- RAG (Retrieval-Augmented Generation): The chatbot uses RAG to improve the quality of its responses. RAG involves two main components: a retriever chain and a conversation RAG chain.
To run the project, follow these steps:
-
Install ollama in you machine and select a llm to use.
-
Install the required dependencies of the project:
pip install streamlit langchain beautifulsoup4 chromadb huggingface_hub
-
Run the Streamlit app:
streamlit run src/app.py
-
Once the Streamlit app is running, enter a website URL in the sidebar and start chatting with the chatbot.
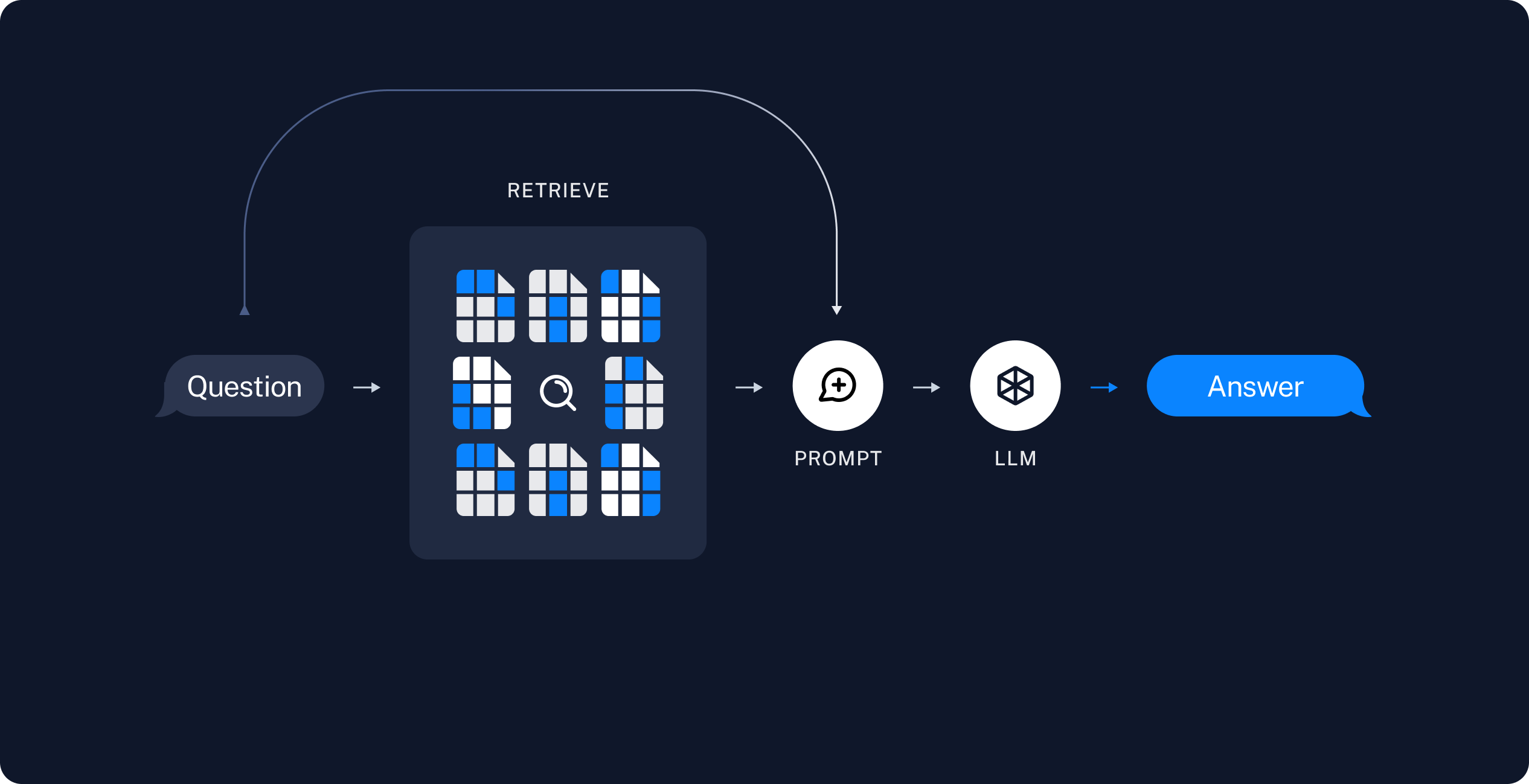
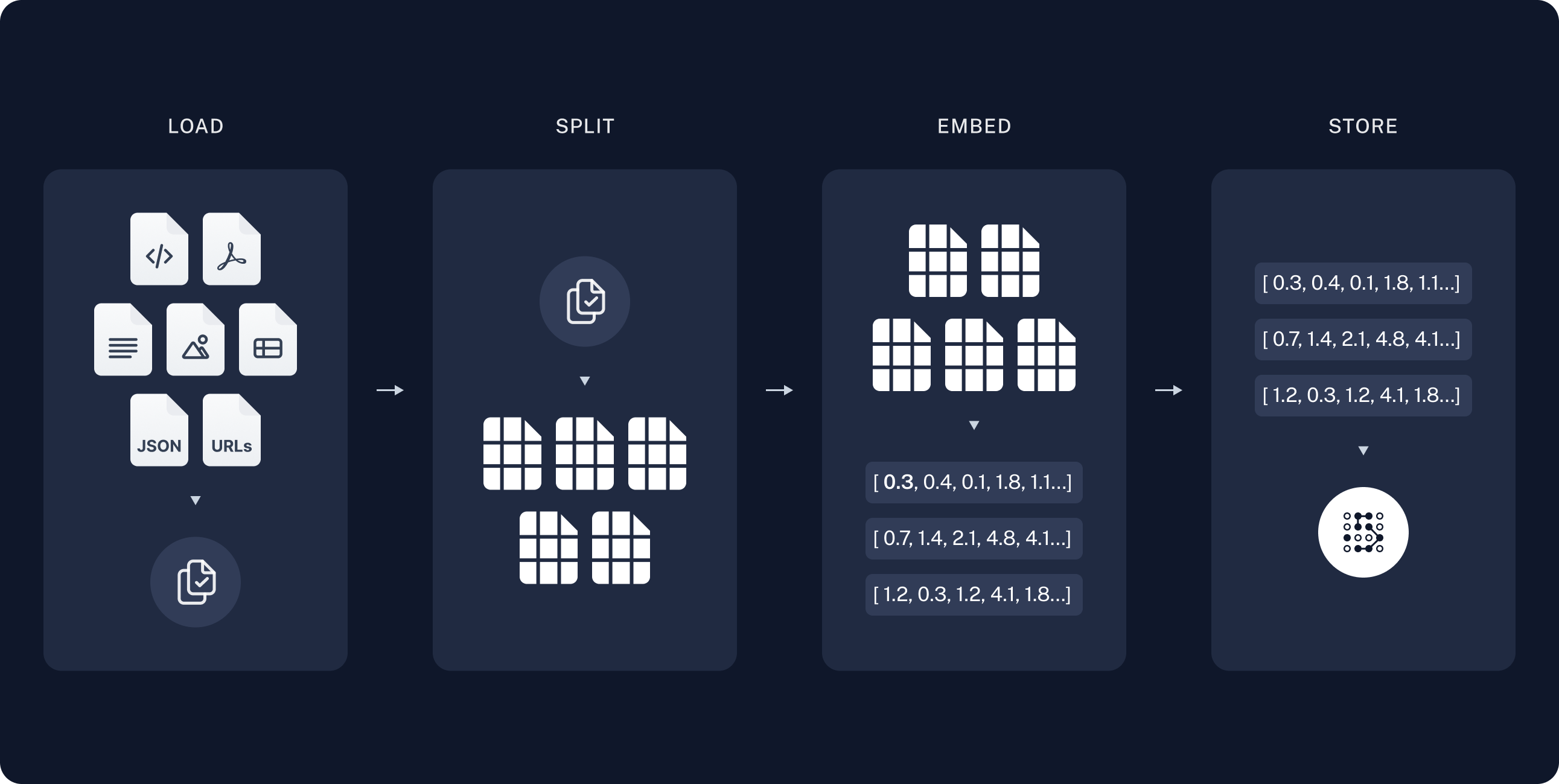
Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response. Large Language Models (LLMs) are trained on vast volumes of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences. RAG extends the already powerful capabilities of LLMs to specific domains or an organization's internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts. Read more here
Follow the LangChain documentation, a typical RAG application has two main components:
Indexing:
Retrieval and generation: