


This repository hosts our work's code VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation.
VIEScore is a Visual Instruction-guided Explainable metric for evaluating any conditional image generation tasks.
🔥 🔥 🔥 Check out our [Project Page and Leaderboard] for more results and analysis!
 Metrics in the future would provide the score and the rationale, enabling the understanding of each judgment. Which method (VIEScore or traditional metrics) is “closer” to the human perspective?
Metrics in the future would provide the score and the rationale, enabling the understanding of each judgment. Which method (VIEScore or traditional metrics) is “closer” to the human perspective?
- 2024 May 23: We released all the results and notebook to visualize the results.
- 2024 May 23: Added Gemini-1.5-pro results.
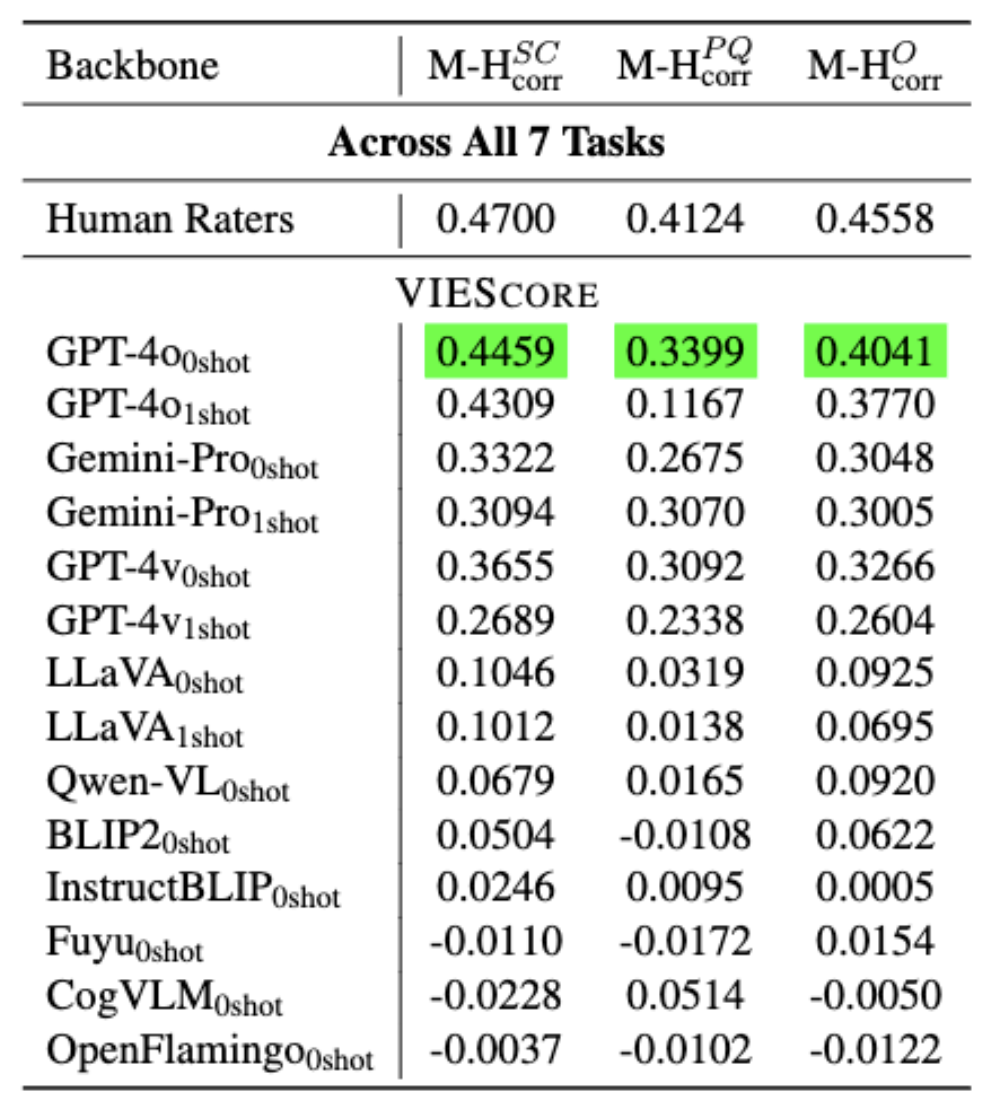
- 2024 May 16: Added GPT4o results and we found that GPT4o achieve on par correlation with human across all tasks!
- 2024 May 15: VIEScore is accepted to ACL2024 (main)!
- 2024 Jan 11: Code is released!
- 2023 Dec 24: Paper available on Arxiv. Code coming Soon!
imagen_museum: helpers to fetch image data from ImagenMuseummllm_tools: Plug-and-Play MLLMs._questions: prompt folder_answers: results folderrun.py: script to run VIEScore.clean_result.py: script to clear nonsense results according tobanned_reasonings.txt.count_entries.py: script to count the number of entries.
$ python3 run.py --help
usage: run.py [-h] [--task {tie,mie,t2i,cig,sdig,msdig,sdie}] [--mllm {gpt4v, gpt4o, llava,blip2,fuyu,qwenvl,cogvlm,instructblip,openflamingo, gemini}] [--setting {0shot,1shot}] [--context_file CONTEXT_FILE]
[--guess_if_cannot_parse]
Run different task on VIEScore.
optional arguments:
-h, --help show this help message and exit
--task {tie,mie,t2i,cig,sdig,msdig,sdie}
Select the task to run
--mllm {gpt4v, gpt4o, llava,blip2,fuyu,qwenvl,cogvlm,instructblip,openflamingo, gemini}
Select the MLLM model to use
--setting {0shot,1shot}
Select the incontext learning setting
--context_file CONTEXT_FILE
Which context file to use.
--guess_if_cannot_parse
Guess a value if the output cannot be parsed.For example, you can run:
python3 run.py --task t2i --mllm gpt4v --setting 0shot --context_file context.txt- Available context files are in
_questionsfolder.
After running the experiment, you can count the results or clean it up:
python3 count_entries.py <your_answers_dir>python3 clean_result.py <your_answers_dir>Refer to analyze_json.ipynb notebook.
Please kindly cite our paper if you use our code, data, models or results:
@misc{ku2023viescore,
title={VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation},
author={Max Ku and Dongfu Jiang and Cong Wei and Xiang Yue and Wenhu Chen},
year={2023},
eprint={2312.14867},
archivePrefix={arXiv},
primaryClass={cs.CV}
}